Issue #168 | The Questions CRO Doesn’t Want To Answer, Part II

Last week’s issue laid out a working framework for testing – the 10 questions every brand / page has to answer, paired with the 2 magnitudes at which any test can address them (10% or incremental; 10x or revolution). Multiply the two and you have a 20-cell matrix that every test can be classified into. That framework was, intentionally, a taxonomy. This week is where we put it to work.
The first useful exercise this framework enables is a historical analysis of your CRO program. Start by pulling (to the extent you can) each test you’ve run over the last 12/18/24 months. The more details you have, the better – but start with what you’ve got.
For each one, ask what question it was designed to impact and at what magnitude (10% or 10x), then classify it into one of the 20 cells in the matrix. Resist the temptation to classify a test (especially a 10% test) as addressing multiple questions; instead, place it under the question it primarily addressed.
While this can feel tedious, the outcome is worth it. ~90% of the time we conduct this analysis as part of an audit, we find that the distribution is heavily skewed. Most tests cluster in 2-3 10% cells, while the empty ones are (almost always) those that require the biggest lift to implement/address (usually: recognition, value, differentiation, trust).
Here’s an example (anonymized from several of our test logs):
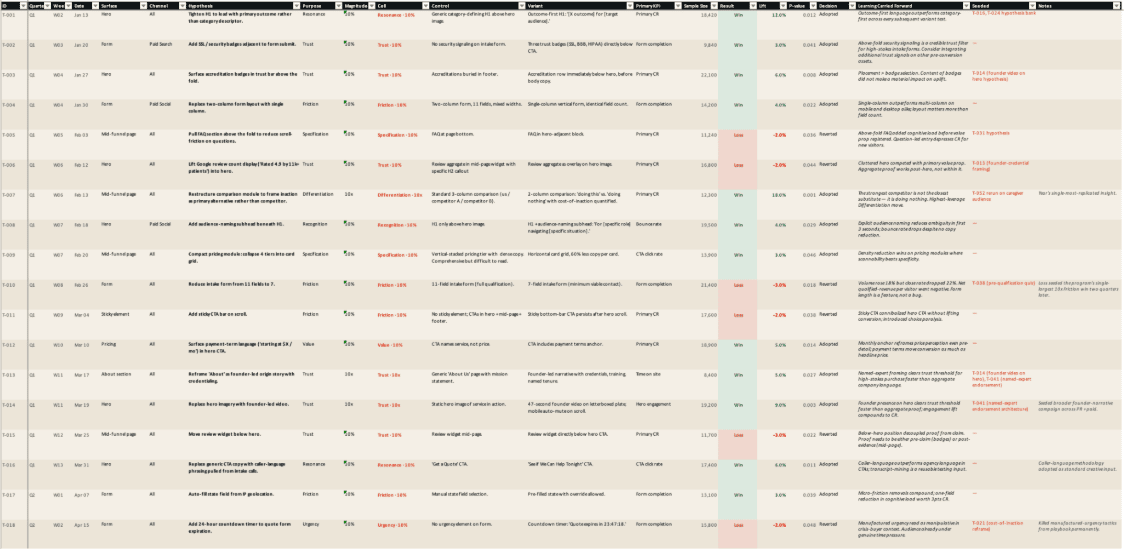
And when you ask Claude to summarize this into a simple table, you get this:
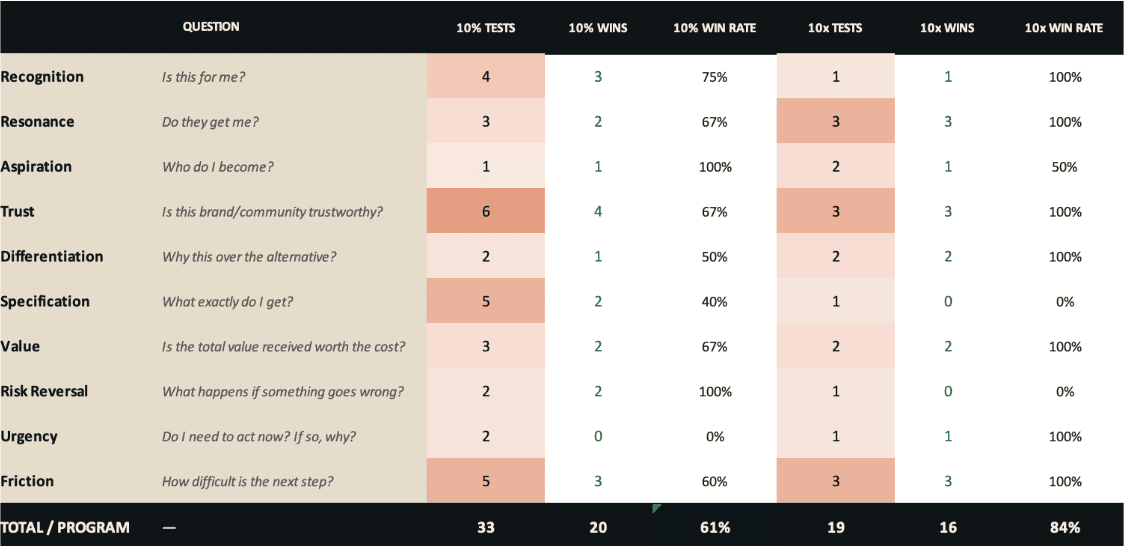
That result isn’t an end in itself; it’s a starting point. The primary goal is to visually illustrate where you’ve been investing your time and resources, so you can decide whether that allocation is the one that maximizes your expected return going forward.
The answer, in most cases is “no” – accompanied by something along the lines of, “why are we spending so much effort there?” To be blunt, the reallocation required is often massive. Most brands find they need to redirect 40%-75% of their testing capacity from 10% cells they’re over-saturated into to the 10x cells they’ve avoided like the plague. That’s an uncomfortable conversation, because it often entails (i) implementing dramatically different tests than what you’ve done historically and (ii) (in the case of 10x tests) moving away from the comfort of isolated tests with statistical rigor in service of making the business better.
Deep down, most brands/marketers know they aren’t pushing the boundaries with their testing program – this exercise simply makes the comfort zone undeniably clear. What you choose to do with that realization determines whether you continue to make small, incremental, safe improvements – or whether you start taking bigger swings and challenging yourself (and your colleagues) to test the other, less-explored questions.
Tests as a Coherent Story
Armed with that blueprint, the temptation is often to just start testing – draw up 3-5 tests that cover the un-addressed cells and get to work. While that’s often tempting, in order to derive maximum value from any program, you need a third concept: sequencing.
The 10 questions from last week’s issue are not independent and isolated. There’s interplay between them. They build on one another.
To illustrate what I’m saying, think about the last time you clicked on an ad for an unknown/unfamiliar brand/product (if you genuinely can’t remember, open up IG and scroll for 2 minutes. You’ll find one). When the LP loads, what are the first questions that come to mind? If you’re honest with yourself, they’re probably some variants of:
- Am I in the right place?
- Is [whatever this is] for someone like me?
In other words, recognition and resonance. If the page fails either of those – if you clicked on an ad for a hair growth system (being a guy in your 30s is fun on IG!), only to find out that the product is for women only (yes, those exist) – it doesn’t matter how fantastic the product is, what a great deal the brand is offering or how much proof or trust signals are present on the page. You’re going to leave, because it isn’t for you.
The same thing holds true for value, trust, aspiration, differentiation, specificity, etc. If the product passes the initial 2 questions, but there are no reviews or 3P credibility (trust), then you’re likely leaving. Ditto if the future state that the product/service offered isn’t what you want or need.
This means the tests you run on a given page aren’t 10 independent optimizations; they’re stations in a story the page is telling. For the story to be successful (and the page to convert), it must be internally consistent. A LP that hits it out of the park on differentiation but fails recognition is worthless, because no one sticks around long enough to read the differentiation section. A page that has reduced friction to near-zero but does nothing to establish trust is a digital slip-and-slide back to whence your visitors came. The ceiling on your conversion rate is like a chain – it’s only as strong as the weakest link (not the average of all 10).
This is the part of the framework that a simple taxonomy view completely misses.
What it implies, practically, is that test selection can’t be reduced to “which test/cell has the highest expected lift.” The right test is the test that addresses the purpose currently bottlenecking the visitor’s progression through the page, regardless of where that purpose sits on a generic prioritization framework. If your recognition is fine and your resonance is broken, no amount of friction reduction will help the page convert better, because your users aren’t even making it to a point in the UX where friction (checkout, form, quiz, whatever) comes into play.
This is also why the tests should cluster sequentially rather than randomly. Think back to your experience visiting an unknown/unfamiliar brand. If the company successfully addresses those first 2 questions above, the next questions you’re most likely to ask are:
- Who do I become if I get this / what does this thing do for me?
- Is this brand trustworthy/credible/legitimate?
- What exactly am I getting? What are they offering, exactly?
Well, that’s aspiration, trust + specificity. Those are the next steps you should run, because that’s the next bottleneck. This isn’t just logical – it’s mathematically optimal. Solving any issues on the first 2 questions maximizes the probability that your visitors will stick around long enough to ask the second set of questions. That means those tests are able to surface a more credible result (because it’s not just true believers or randoms making it down the page) faster.
Most critically: these tests, taken as a sequence, should tell a coherent story about what the team has learned about the page’s relationship with its audience. The brands that realize outsized CVR/AOV/Lead Quality gains over time aren’t running random tests. They’re running a sequence of tests that progressively resolve the questions their audience is asking, from the top of the funnel down, at the magnitude required to move each question’s needle. More often than not (and this is where this framework can be uncomfortable for the statistically-forward among us), that means doing a lot more 10x tests on the foundational questions.
Different Audiences, Different Questions
The 10 questions are universal in that they apply to every commerce or lead-gen page. They aren’t universal in how they get answered. That’s where audience insights come into play.
The same question, asked by different audiences, has different answers.
Recognition for a 28-year-old DTC apparel customer is a different visual and verbal vocabulary than recognition for a 65-year-old senior living prospect. A B2B SaaS buyer requires fundamentally different trust signals than a first-time supplement shopper. Resonance – by definition – depends entirely on which audience the page is for, because it’s the explicit alignment of the page’s content with the user’s internal state (aside: this is why you should have different LPs for different audiences/offers).
Layer all that together and you have a 3D framework:
- The 10 Questions (X-axis): the questions the page answers
- The 2 Magnitudes (Y-axis): whether the test optimizes or reframes the answer
- The Audience (Z-axis): which audience segment the answer is being constructed for
That 3rd dimension is (quite possibly) the most under-discussed aspect of CRO, because it brings Simpson’s Paradox into play. The reality is that many tests that show no lift across your broader audience often do show a lift among certain sub-segments – but, because no-one bothered to dig deeper, the little nugget of insight for that specific segment goes un-mined.
The second, and related, issue is that when testing, most brands construct answers for a persona – an audience composite that resembles no individual visitor – and then tailor their answers to it. The result is a LP that converts decently well for everyone, but doesn’t excel with any segment.
The brands that win run separate matrices for separate audiences.
They build a different page for each meaningfully distinct audience – each with different recognition and resonance, tailored trust signals, etc. – and they test within each audience’s matrix, against that audience’s specific answers. This is what platforms like Replo allow you to do at scale – spin up tailored LPs for each individual audience segment so you can do this at scale.
This is the fundamental reason brands with strong audience segmentation tend to dominate brands without it: they’ve developed a system (intentionally or otherwise) to optimize their answers for each segment, vs. trying to be all things to all people on each page.
Why Testing Deserts Happen
Whenever we present an audit that shows an entire group of cells completely untouched, the first question is, without fail, “why in the world didn’t we try anything there?” They’re usually referring to 10x tests in resonance, trust, differentiation, value or risk mitigation.
Regardless of the brand, the same 3 reasons tend to be cited:
#1: political cost. A 10x resonance test is, functionally, a proposal to re-build the LP in a style, voice & tone that the brand team or founder might hate. A 10x trust test is a proposal to replace the trust mechanism (reviews, UGC, ratings, 3P credibility) the brand has built its identity around with one that a specific audience finds credible. That might not sound like much, but try telling an eComm founder to remove all the star reviews and media logos from their LP, then replace them with UGC videos from TikTok. They’ll call you insane. Ask me how I know. But the reality is that a certain audience segment – younger Gen Z – has been trained to see right past star ratings. They think media placements are a scam (and no matter what publications you cite, half of them don’t trust them). But, other people who look exactly like them, talking on TikTok? Somehow, that works for them – even though it terrifies the brand team.
#2: time horizon. 10x tests take more time to resolve than 10% tests, simply because the variance is wider and the foundational nature of the change means downstream effects take longer to come into view. An agency that’s expected to conduct X tests each month will systematically prefer 10% tests, because they are both faster + easier to report.
#3: expertise asymmetry. A 10% friction test can be designed by any reasonably competent marketer or CRO practitioner. A 10x resonance test requires someone who has a deep understanding of the audience, strategic creative judgment + the ability to construct a page-level argument that gets the founder/brand team/CMO on board. Candidly, finding people who can do that is difficult. Most teams are full of people who can do the straightforward 10% test, but would be completely lost if you asked them to fundamentally re-think anything.
The fix is the analysis from the beginning of the issue: explicit allocation of testing capacity across the matrix, alongside a commitment in the strategic and creative capacity required to execute the more complex / bolder 10x tests.
Longtime readers will likely recall that this is the same set of dynamics I described in The Art and Science of Media Buying – the systematic underinvestment in high-leverage work that requires judgment, in favor of low-value, high-output volume work. The pathology recurs because the incentive structure recurs (aside: if anyone doubts that Charlie Munger was right about incentives, explain this). The fix is the same, too: separate the work that can be systematized from the work that requires judgment, then protect the second from being crowded out by the first.
Getting From Where You Are To Where You Want To Be
A working architecture, built around this framework, has 5 components:
- Classification of every existing test. This is the audit described above. Until you’ve done it, every other component is operating on some combination of memory + assumptions, rather than actual data.
- Explicit purpose-and-magnitude assignment for every test. Every test should specify, in two lines, which of the 10 questions it addresses and whether it’s a 10% or 10x test. Tests that can’t be assigned should be redesigned until they can. Tests that legitimately address multiple purposes should be split, because the multi-purpose test is the one whose results you can’t generalize from.
- Intentional allocation across the matrix. The right allocation varies by brand, program, goals & challenges. That being said, a useful starting heuristic is:
- 30% of capacity on 10x tests across the 4 foundational questions (recognition, resonance, trust, differentiation)
- 50% on 10% tests across all 10 questions
- 20% reserved for opportunistic 10x tests in the 6 purposes when audience research or competitive intelligence reveals an opening.
The exact percentages matter less than the principle: you’re making explicit allocation rather than letting the path of least political and creative resistance determine what you test – and you’re getting explicit buy-in from the executive team around those tests.
- Sequencing. Tests should be run in an order that aligns with how your audience processes/progresses through the page, with later tests building on the results established by earlier ones. From a practical standpoint, this means the initial tests on a problematic page should usually lean heavily on recognition and/or resonance, with friction and specification deferred. This is counterintuitive: friction is usually the first thing marketers/agencies want to test on a mediocre-performing page (“just reduce the number of fiends on the form” or “move the checkout from 3 steps to 2” or whatever).
- Measurement against a relevant baseline. Test wins should be measured vs the variant they replaced. The program is measured against the conversion rate of the funnel as a whole over a meaningful time horizon (largely depends on traffic volume, sales cycle, etc.). Winning tests at a 45% clip doesn’t mean a damn thing if the overall funnel’s conversion rate isn’t moving. The goal isn’t to find “winning” tests; the goal is to make more money. In fact, if test wins aren’t making you more money, that’s your first clue that something is amiss.
What This Framework Does Not Cover
Before I close, an important caveat – and (probably) the most under-discussed one in CRO discourse generally.
Everything I’ve written so far is about the first win. The first purchase. The initial inquiry.
The visitor arrived, the page did its job, the conversion occurred. That’s it. And that’s where most CRO programs end. But it’s also, in many businesses, where the actual economic question is just beginning.
A conversion is not a customer. A lead is not a closed deal. A first purchase (for many businesses) is not a profitable relationship. In most categories, the difference between a brand that scales profitably + sustainably and one that bangs its proverbial head against the CAC wall has nothing to do with the initial CVR. It has everything to do with what happens after that magical initial moment – the post-conversion experience, the nurture sequence, the onboarding flow, the repeat purchase mechanics, the referral and retention structure. All of that is every bit as important – if not more important – than any CRO work.
Each of the 10 questions I described applies again, identically, to the post-conversion environment. The questions don’t go away when the visitor converts. They just morph into something else. For example, after someone fills out a lead form, they’re now asking:
- Did this go to the right place? That’s recognition.
- Is the company going to treat me like a real person or run me through a generic intake script? Resonance.
- Do these people actually know about my unique situation? If I [work with them, use them, choose them], what will that mean for me? Aspiration.
- Are these people credible / knowledgeable / expert enough to solve my issue? Trust.
- Why should I take their call rather than the 4 other firms I also submitted to? Differentiation.
- What exactly are they going to do to resolve my problem? What’s their solution look like? How does it work? Specification.
- Is this going to be worth the cost (money, time, effort)? Value.
- Why should I respond to their email today rather than next week? Urgency.
- What happens if something goes wrong? Risk mitigation.
- How easy do they make it for me to keep this moving? Friction.
Likewise, someone makes a first purchase, they’re asking:
- Did my order actually go through and is it real? Recognition.
- Did this brand notice that I was the one who bought, or am I just another brick in the wall? Resonance.
- Are they going to ship this on time and is it going to be what I expected? Trust.
- Why should I keep buying from them instead of [competitor/alternative]? Differentiation.
- What did I actually buy and what comes with it? Specification.
- Was this worth what I paid? Value.
- Why should I open the next email? Urgency.
- How easy do they make it to repurchase, refer, or escalate when something goes wrong? Friction.
Those are the same questions, just applied in a different part of the customer’s journey. The same magnitude distinction (most post-conversion testing is 10% tweaks to email subject lines or thank you page copy, when the 10x opportunities are re-thinking the entire post-conversion sequence). Same audience overlay (a high-LTV customer’s post-conversion needs are categorically different from a low-LTV customer’s, and most brands’ nurture flows treat them identically).
By the same token, 95% of thank you pages are resonance-0 / trust-0 / specification-0 / friction-10 disasters. Your new prospect/customer just expended a ton of effort. They went out on a limb. They gave you money or information or both….and your response is “Submission Received” or a page reload. What? I wrote about this in Issue #145, but the Cliff Notes are: the TY page is an impulse zone – it’s the checkout aisle at the grocery store. Your new lead/customer is at peak attention, peak commitment & peak willingness to engage with whatever comes next. Almost nobody capitalizes on it. Instead, most brands dump their hard-won customers/leads into a generic void, then wonder why their email open rates suck. I’m told, by my gen-z colleagues, this is the marketing equivalent of ghosting someone after a hookup.
The post-purchase email sequence has the same problem. So do nurture flows. So does onboarding. So does the repeat-purchase experience. So do retention emails. They’re all running on whatever someone built 2 years ago, with (if you’re lucky) an occasional A/B test on subject lines. Meanwhile, there are golden opportunities to re-think/re-architect entire flows, post-conversion experiences, retention experiences that go by the wayside.
The framework I’ve described in this piece – 10 questions, 10%/10x, Audience-Specific, Sequencing – applies to all of it. The matrix doesn’t care whether it’s applied to a PDP or a thank-you page or an email flow. The only thing that changes are the questions your audience is asking and the answers you’re providing.
If you’ve read this far and you’re already thinking about which 10x tests you want to attack on your acquisition funnel, good. Now do the same exercise on your post-conversion funnel. Pull every email, every page, every touchpoint between the initial lead + qualification (or 1st purchase and repeat). Classify them into the matrix. Look at the distribution. I will bet you a dinner that the distribution looks even worse than the acquisition side, simply because at least the acquisition side is doing some kind of CRO. The post-conversion side, in most brands, has nothing.
The beauty of this framework is that it’s intended to help you surface these connections between different phases of the customer journey/experience. The questions are the same, so (theoretically) there’s applicability of results to other parts of your marketing program.
Here’s an example (Claude helped summarize + anonymize) from one test log:
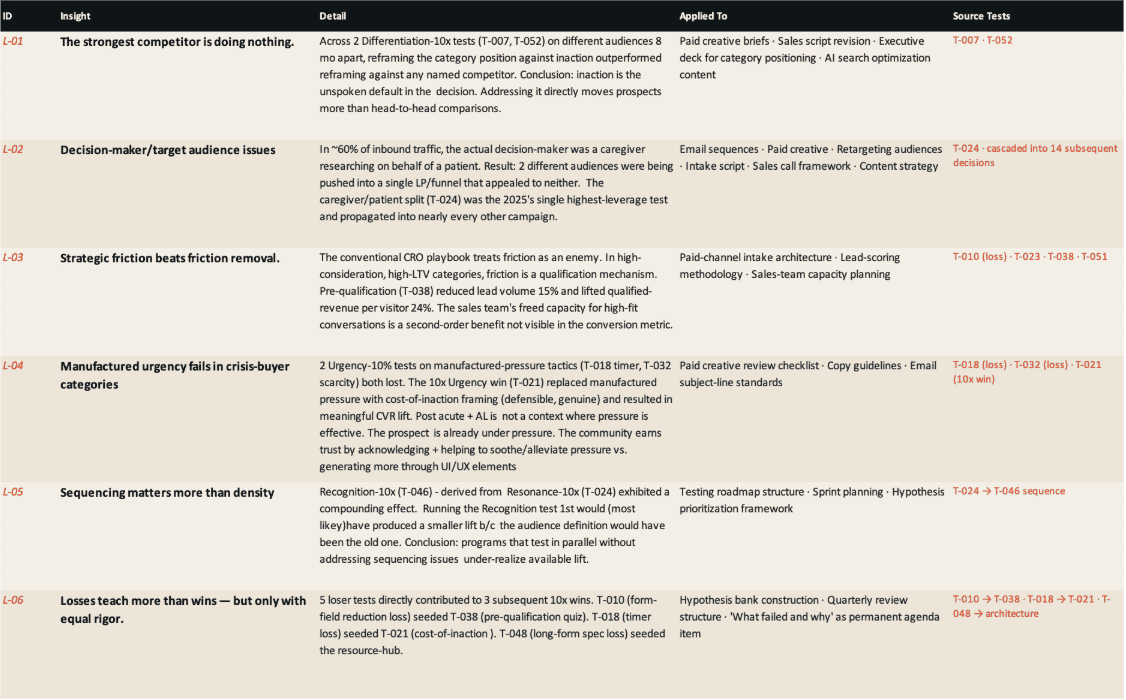
Notice how urgency-related tests on the LP produced an insight (manufactured pressure tactics have a negative effect on CVR for post-acute audiences) that was subsequently applied to copy guidelines AND email. Strategic friction tests were applied to both LPs + lead scoring. By anchoring every test on a question, you can apply learnings about how your audience (or a segment of your audience) wants that question answered at every touchpoint where it’s asked.
Is it scientifically defensible? No. But I’m not in the business of publishing papers in academic journals. I’m in the business of helping our clients get more leads and make more money. This does that.
If I could summarize everything I’ve written the last 2 weeks, it’d be this:
The reason most CRO programs are ineffective isn’t that the people running them are bad at their jobs; it’s that they’re operating without a coherent, audience-centric framework, in an environment that rewards the wrong kind of work, anchored to a methodology that systematically suppresses the exact kind of interventions that produced outsized results – all in the name of unnecessary scientific rigor.
This framework is not a silver bullet. The 10 questions aren’t going to create your tests for you (you still have to do the work, understand the audience + design the test) and the 10%/10x distinction isn’t going to magically alleviate the cost of running crazy, out-of-the-box, unconventional-as-anything tests. What it will do is make the structural problem visible. My belief has always been that a problem clearly articulated is a problem half solved – so, by my logic, I got you half way with this issue.
The other half is up to you. But I do hope this helped.
Cheers,
Sam

